Использование богатой постпоисковой статистики для веб-поиска
Перевод статьи "Through-the-Looking Glass: Utilizing Rich Post-Search Trail Statistics for Web Search".
Обзор
С ростом популярности тулбаров увеличивается важность правильного использования поведенческих данных пользователей, хронящихся в логах. Анализ посткликовых (при переходе на сайт со страницы поиска) поисковых маршрутов показывает важность знаний о пользовательских предпочтениях и помогает улучшить существующие поисковые системы. Тем не менее значимость свойств пользовательских маршрутов для улучшения ранжирующих моделей по-прежнему недооценена. Мы провели крупномасштабное исследование и оценку большого числа пользовательских данных и можем заключить, что анализ пользовательских данных, основанных не только на кликах в SERP’е, могут значительно улучшить ранжирующие модели.
1. Введение
За последние годы информация о пользовательском поведении начинает играть всё большую роль в информационном поиске. Наиболее известный способ получить доказательства пользовательских предпочтений и удовлетворения — анализ логов пользовательских кликов. Хотя они предоставляют большой объем пользовательских фидбэков, их значение и надежность ограничены, т.к. большая часть пользовательской активности приходится на действия за пределами страницы с результатами поиска.
С возросшей популярностью браузерных тулбаров стало возможно частично компенсировать недостаток данных о посткликовом поведении пользователей. Было показано, что базовая статистика пользовательского взаимодействия с веб-страницами, такие как время пребывания на странице, могут дать хорошие данные для ранжирования документов. Тем не менее общая последовательность документов одной и той же информационной потребности, которая просматривается после клика на странице результате поиска, которая так же называется “постзапросный поисковый маршрут” (post-query search trail), не является досточно изученной в качестве источника потенциального улучшения ранжирования документов. Мы предполагаем, что существенный анализ поисковых маршрутов может помочь улучшить существующие модели.
Мы провели крупномасштабное исследование различных свойств поисковых маршрутов, которое продолжает предыдущие изучения данных пользовательского поведения и их пользу для веб-поиска. Мы представили поисковые маршруты, как древовидную структуру с кликовыми результатами в качестве корней этого дерева, а переходы по ссылкам в качестве ветвей. В качестве “деревьев” поисковые маршруты обладают следующими характеристиками: число узлов, глубина, ширина, средняя длина ветви. В добавление к этим свойсвтвам маршрутов мы изучали и оценили некоторые новые свойства: количество шагов в маршруте с временем неактивности пользователей. Некоторые из этих свойств были теоретически изучены в уже существующих исследованиях, но не были применены в поисковых метриках. Объединенные на документном или доменном уровне кликовых результатов, большинство свойств улучшают представление основной поисковой модели, используя посткликовые свойства. Этот результат поддерживает вышеупомянутое предположение: на основании продолжительности маршрутов мы способны узнать больше о кликовой релевантности. Суммируя вышенаписанное, польза этой статьи, во-первых, в том, что мы провели крупномасштабное исследование обширного числа свойств поведенческих маршрутов и их польза для веб поиска, во-вторых, мы показали, что изучение характеристик поисковых маршрутов может дать дополнительные доказательства, необходимые для информационно-поисковых задач.
2. Связанность работы
С точки зрения зрения перспективы развития поисковых систем, наиболее практичный способ включить информацию о пользовательском поведении в существующую ранжирующую формулу — это разрабатывать новые свойства, отражающие различные качества взаимодейтсвия пользователя с сайтом. Одна из первых работ об использовании поведения юзера, основанное на сборе данных из браузеров, для улучшения качетсва поиска это [1]. Среди остальных поведенческих свойств авторы изучают некоторую базовую статистику пользовательского взаимодействия со страницами, в том числе, и время пребывания. Более трудноуловимые свидетельства пользовательского взаимодейтсвия могут быть получены с помощью анализа скроллинга страницы и движения мыши [4]. В своем исследовании мы также решили выйти за рамки показателя dwell time, как основного доказательства активности пользователя, более того, мы шагнули намного дальше первой страницы в поисковом маршруте. Другим способом использования данных о поведении пользователей является освоение формулировок начальных поисковых запросов, с которых начинается поисковый маршрут пользователя, ведущий к анализируемому документу [2].Комплексный анализ всего поискового маршрута дает больше пользы, чем сравнение первой и последней страницы маршрута по различным критериям, таким, как релевантность, тематический охват, разнообразие тем, новизна и полезность [8]. В своем исследовании мы представляем поисковые маршруты как древовидную структуру, как это было ранее сделано в работе Р.У.Уайта и С.М. Друкера [7], также мы воспользовались некоторыми основными графами свойств из этой работы. Бинарная особенность кликового результата, которых идентифицирует присутствие любого пост-кливого следа, был использован для обучения классификатора обнаружения шумов в кликах [8].
3. Информация
Все эксперименты, описанные в этой работе, были выполнены с использованием информации о пользовательском поведении, основанная на хранящейся информации в анонимных логах из поискового тулбара на популярном во всем мире браузере, который используют миллионы людей в различных странах. Каждая запись в этом логе содержит (анонимно): тулбарный пользовательский идентификатор, временную метку и детали действий в браузере: введенные звпросы, URL-адреса посещенных страниц, закрытие браузерного окна. Мы использовали все записи в логе за 3 месяца: с 11 декабря 2012 по 10 марта 1013. Данные содержат 3млн. пользовательских запросов, 5,3 млн. поисковых маршрутов, 16 млн. визитов на 2,7 млн. различных страниц.
Из полученной информации мы извлекли поисковые маршруты, которые начинались с пользовательских запросов и состояли из последовательных визитов на веб-страницы одним и тем же пользователем, имеющую общую информационную потребность. Чтобы уменьшить шум от страниц, которые не входили в информационну потребность пользователя, мы завершали поисковый маршрут при одном из условий:
- Пользователь задавал новый запрос.
- Пользователь переходил на домашнюю страницу, вводил URL-адрес в адресную строку или переходил на страницу, используя закладки.
- Пользователь не проявлял никакой активности более чем 30 минут.
- Пользователь закрывал окно браузера.
Весь этот список также используется для определения поискового маршрута в работе Р.У. Уайта и С.М. Друкера [7], за исключением одного правила — «проверить электронную почту или залогиниться в сервисе». Мы считаем, что данные действия могут быть логичным продолжением поискового маршрута, т.к. пользователь в рамках своего запроса может переходить по гиперссылкам веб-сайтов, требующих аутентификации.
4. Особенности поисковых маршрутов
В этой части мы коротко опишем путь поисковых маршрутов на подобие тому, как это сделано в [7]. Как мы уже заметили выше, мы трактовали каждый поисковый маршрут, как древовидную структуру. Узлы — это уникальные страницы, а направления ребер — переходы по ссылкам. Переходы пользователей вперед по ссылкам отображены, как движения вдоль по веткам деревьев. Если кто-либо из пользователей повторно посещает страницу в рамках одного маршрута, происходит продолжение ветвей. Если пользователь возвращается на страницу результатов и кликает на новый документ, начинается новое дерево. Посмотрите на пример на рисунке 1. В следующей части мы опишем свойства, с помощью которых маршрут может быть охарактеризован, и которые мы использовали в качестве ранжирующих факторов в данном исследовании.
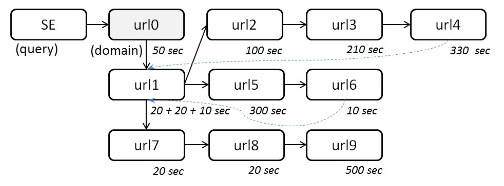
Рисунок 1: поисковый маршрут, представленный в качестве дерева.
- узлы (Nodes) = 10
- глубина (Depth) = 4
- ширина (Breadth) = 3
- длина ветви (Branch length) = 3
- шаги (Steps) = 12
- повтороных просмотров (Revisits) = 2
- время (Time) = 1590
- удовлетворенных шагов (Satisfied steps) = 6
- длинных шагов (Long steps) = 3
4.1 Характеристики графа
- Подсчет узлов (Nodes count). Общее число узлов в дереве соответсвует количеству уникальных страниц, просмотренных пользователем в течении постпоискового маршрута. Большое значение данной характеристики может указывать на то, что первая страница в маршруте, предложенная поисковой системой в результатах, была недостаточно качественной для удовлетворения пользовательской потребности, побуждая его переходить вглубь по ссылкам. С другой стороны, большое значение количества узлов более типично для маршрутов по информационным запросам, где информационная потребность не может быть целиком удовлетворена одной веб-страницей.
- Глубина (Depth) — это расстояние между корнем дерева и наиболее дальним узлом, где расстояние между двумя узлами — это количество ребер в наиболее коротком пути между узлами. Глубокие деревья предположительно более типичны для маршрутов, которые воспроизводят просмотр на сайтах, страницы которых последовательно соеденены ссылками “вперед” и “назад”. Это может быть в случае, если контент на сайте разбит на несколько страниц, имеющих строгую последовательность.
- Ширина (Breadth) пути в дереве — это количество листьев. Листья (Leaves) представляют достигнутые страницы, визиты на которые никогда не были продолжены последующими переходами. Ширина маршрута совпадает с количеством ветвей, это было рассмотрено в [7]. Больше значение данного признака может означать, что лежащая в основе информационная потребность имеет множество аспектов, пользователь выполняет поиск в исследовательской манере или домен содержит маршрутные страницы, которые расположены неудобным способом.
- Средняя длина ветви (Average branch length). Мы разложили поисковый маршрут на сегменты, каждый следующий сегмент начинается с повторного визита посещенной страницы и продолжает последовательность последующих ссылок. Для каждой цепи мы нашли ее длину, которая является количеством ребер, из которых сделана цепь. Мы игнорируем цепи длиной 1, т.к. они не формируют новые ветви деревьев. Средняя длина ветви получена как средние длины всех цепей, которые соответствуют различным ветвям дерева. Что заслуживает упоминания, это то, что данное значение так же равно ((узлы-1)/ширина)+1.
4.2 Особенности передвижения
Кроме вышеперечисленных особенностей, которые отображают свойства дерева маршрута, есть еще некоторые свойства, отражающие качество передвижения юзера по маршруту.
- Количество шагов (Number of steps) — это ощее количество переходов, сделанное пользователем в маршруте. Это особенность такая же, как и количество узлов, о чем было написано выше, но отличие в том, что в данном случае считаются повторные визиты.
- Количество повторных визитов (Revisits) — количество заново просмотренных страниц в течении маршрута. Данный показатель можно рассматривать как оценку запутонности маршрута. В действительности, большое значение повторных визитов означает, что пользователь часто возвращается на предыдущую страницу, вместо того, чтобы переходить по ссылкам на новые страницы или для того, чтобы получить какую-то новую информацию, которая не была получена получена во время первого посещения страницы.
- Разнообразие (Diversity) — количество различных доменов второго уровня представленных на страницах в маршруте.
- Количество удовлетворенных шагов (Satisfied stpes) и количество длинных шагов (Long steps) — число шагов в маршруте с 30 и 300 секундной задержкой на страницах. Таким образом, мы определяем удовлетворенные шаги таким же образом, как это сделано в [6]. Удовлетворенные шаги говорят о страницах, которые более других привлекли внимание пользователей.
Рисунок 1 показывает поискового маршрута и показывает значения всех его свойств, описанных выше.
4.3 Объединение характеристик
После того, как все характеристики были получены для каждого маршрута, мы объединяем все характеристики одним из двух возможных способов: на уровне првого документа в поисковом маршруте (объединение на уровне URL) и объединение на уровне документа домена (объединение на уровне домена). В результате для каждого типа, описанного выше, мы высчитываем среднее значение (AV), стандартное отклонение (STD), 10-й и 90-й персентиль (т.е. нижний и верхний дециль соответственно), минимальное и максимальное значения (MIN, MAX) и использовали их в качестве факторов ранжирования. В следующей части мы описываем, как полученные характеристики зависят от тематики домена документа.
5. Характеристики и доменные тематики
В этой части статьи мы рассмотрим, как зависят значения характеристик поисковых маршрутов от тематики входных страниц. Для этого мы взяли нашу собственную базу доменов вручную отсортированную по тематикам. Мы применили наивный байесовский классификатор, обученный на основании юниграмных (1 n-грамма) характеристик доменных страниц. Этот классификатор анализирует все домены второго уровня, которые попали в нашу выборку поисковых маршрутов, и присваивает каждому домену определенную тематику. Мы взяли типовые характеристики на уровне домена (см. часть 4.3), и рассчитали для каждой из них средние значения в рамках определенной тематики. Таким образом, для каждой тематики мы получили свой средний показатель всех ранее рассматриваемых характеристик. Мы отсортировали все темы по среднему значению каждой характеристики и отобразили результаты в таблице № 1.
| Узлы | Глубина | Ширина | Длина ветви | Шаги | |||||
| Частная жизнь | 2.20 | Частная жизнь | 1.91 | Спорт | 1.26 | Частная жизнь | 2.65 | Частная жизнь | 2.68 |
| Спорт | 2.15 | Отдых | 1.85 | Отдых | 1.24 | Отдых | 2.63 | Спорт | 2.64 |
| Отдых | 2.14 | Спорт | 1.83 | Частная жизнь | 1.24 | Авто | 2.59 | Отдых | 2.63 |
| Авто | 2.06 | Авто | 1.8 | Авто | 1.21 | Бизнес | 2.58 | Авто | 2.54 |
| Бизнес | 1.98 | Бизнес | 1.76 | Трудоустройство | 1.21 | Спорт | 2.58 | Бизнес | 2.42 |
| Повторные визиты | Разнообразие | Удовлетворенные шаги | Длинные шаги | ||||
| Развлечения | 0.7 | Компьютеры | 1.13 | Общество | 0.24 | Отдых | 1.15 |
| Спорт | 0.56 | Развлечения | 1.12 | Медиа | 0.2 | Общество | 1.11 |
| Частная жизнь | 0.55 | Трудоустройство | 1.12 | Развлечения | 0.2 | Авто | 1.1 |
| Отдых | 0.54 | Общая | 1.12 | Наука | 0.2 | Спорт | 1.08 |
| Авто | 0.53 | Культура | 1.09 | Отдых | 0.19 | Развлечение | 1.05 |
Таблица 1: Тематики с наиболее высокими показателями значений по доменам.
Как видно по таблице, некоторые тематики естественным образом расположены внизу топа по многим показателям поискового маршрута. Например, пользователь, который просматривает сайт по автомобилям не знает наверняка какой именно автомобиль он ищет. Пользователь также охотно просматривает различные страницы, посвященные комплектациям. Подобные выводы можно сделать относительно показателей глубины, широты и количества шагов. Наибольшее количество шагов наблюдается в таких тематиках, как общество, медиа и наука, чей контет — это длинные статьи для внимательного изучения. Также есть интересные закономерности касательно тематик, находящихся внизу таблицы. Среди тематик с низким показателем удовлетворенных шагов находятся частная жизнь и авто, при этом данные тематики имеют высокий показатель по количеству шагов. Это означает, что несмотря на большое количество просмотренных страниц пользователи редко задерживаются надолго на каких-то определенных страницах. Эти результаты означают, что характеристики поисковых маршрутов могут использоваться для идентификации тематики сайтов, что может быть применено в поисковых системах. В следующей части пойдет речь о том, как данные о поисковых маршрутов могут использоваться в ранжировании.
6. Оценка
Для оценки характеристик поисковых маршрутов мы взяли обширную базу случайных поисковых запросов из реально существующей поисковой системы. По каждому запросу были взяты топовые документы из лидирующей поисковой системы. Документы были оценены специальными людьми по шкале: «превосходно», «отлично», «хорошо», «неплохо» и «плохо».
В общей сложности было обработано 50к запросов и 1,5 млн пар запрос-документ. Присваивая оценки, мы использовали градиентное дерево решений Фридмана (Friedman's gradient boosting decision trees, метод машинного обучения) как модель ранжирования. Мы проверили эффективность предложенных факторов со стандартным набором факторов (Базовым): вариация BM25, Page Rank, CTR документов и домена, 7 модификаций времени пребывания (dwell time), описанных в таблице 4.1:
- TimeOnPage (время на странице)
- TimeOnDomain (время на домене)
- AvarageDwellTime (среднее время пребывания)
- DomainDeviation (отклонение от среднего времени пребывания по домену).
Данные базовые характеристики достаточно информативны, легко интерпретируются и включают в себя широкий спектр известных на настоящий момент особенностей, основанных на показателях времени пребывания пользователя на документе по запросу (dwell time).
Мы поделили все запросы в базе на 2 равные части: первую — для обучения, вторую — для оценки.
В таблице № 2 показана производительность трех моделей обучения:
- Basic — базовый набор характеристик;
- Basic+Domain — базовый набор характеристик + характеристики маршрута на уровне домена
- Basic+URL — базовый набор характеристик + характеристики маршрута на уровне URL.
| Запросы | Basic | Basic+Domain | Basic+URL | ||
| Все | 57,57% | 57,95% | +0,66% |
58,05% | +0,82% |
| 1-слов. | 67,62% | 67,78% | +0,23 | 67,47% | -0,21% |
| 2-слов. | 64,72% | 64,89% | +0,27% | 64,91% | +0,29% |
| 3-слов. | 59,08% | 59,63% | +0,93% | 59,48% | +0,67% |
| 4≥ слов. | 50,15% | 50,75% | +1,2% | 50,92% | +1,54% |
| популярные | 66,91% | 67,16% | +0,36% | 67,11% | +0,30% |
| непопулярные | 49,88% | 50,34% | +0,91% | 50,55% | +1,33% |
Таблица 2: Показатели NDCG@10, полученные на основе стандартных характеристик, а также с добавлением к ним характеристик поискового маршрута, объединенных на уровне URL и домена. Формируют 45.18% набора данных, коэффициент запросов ≥ 10 в неделю считать популярным. Различия, выделенные жирным шрифтом, — это статистически значимые на уровне достоверности в 0.99%.
Как видно из таблицы, использование характеристик поискового маршрута как на уровне домена, так и на уровне страницы способствует повышению эффективности модели ранжирования.
Модель, обученная на основе базового набора характеристик без учета 7 модификаций dwell time, обладает показателем N DCG @ 5 = 55,9%. Следовательно, показатели маршрута на уровне страницы повышают качество результата на 0,82% вдобавок к 2,9%, полученным за счет dwell time.
Мы также измерили производительность трех моделей отдельно по разным классам запросов. Было обнаружено, что характеристики поискового маршрута еще больше влияют на низкочастотные и узкоспециализированные запросы. Это можно объяснить следующим образом: показатели маршрутов, объединённые по домену и страницам, проецируют пользовательские предпочтения на более сложные и редкие ситуации, где поведение пользователей мало изучено. Для того чтобы подтвердить эту догадку, мы разделили все изучаемые запросы на четыре почти равные части в зависимости от наличия данных о поисковых маршрутах (начиная с маршрутов, состоящих из минимум 2-х шагов от поискового запроса). Полученные результаты представлены в таблице № 3. В ней видно, что факторы поискового маршрута имеют значительное влияние на сложные запросы.
| Запросы | Basic | Basic+Domain | Basic+URL | ||
| Группа 1 | 44,11% | 44,60% | +1,1% | 44,98% | +1,97% |
| Группа 2 | 59,61% | 60,01% | +0,67% | 59,85% | +0,39% |
| Группа 3 | 65,84% | 66,12% | +0,42% | 66,09% | +0,37% |
| Группа 4 | 67,01% | 67,34% | +0,49% | 67,31% | +0,45% |
Таблица 3: Показатель NDCG@10, полученный при четырех различных уровнях доступности данных, где группа 1 считать наименее доступной, а группа 4 — максимально доступной.
В таблице № 4 показан топ-10 характеристик, отсортированных в зависимости от их влияния (измеряется уровнем улучшения функции потерь на протяжении всего процесса обучения). Показатели поискового маршрута выделены курсивом.
| # | Basic+Domain | Basic+URL | ||
| 1 | QueryDomCTR | 20.2 | QueryDomCTR | 21.7 |
| 2 | BM25 | 17.7 | BM25 | 20.2 |
| 3 | QueryUrlCTR | 14.2 | QueryUrlCTR | 13.1 |
| 4 | QDwellTimeDev | 11.0 | QDwellTimeCTR | 10.9 |
| 5 | PageRank | 5.2 | AvSatSteps | 5.1 |
| 6 | AvSatSteps | 2.5 | PageRank | 4.7 |
| 7 | AvDwellTime | 2.2 | TimeOnDomain | 2.6 |
| 8 | DwellTimeDev | 1.7 | ComulativeDev | 1.8 |
| 9 | 90thDwellTime | 1.4 | 90thDwellTime | 1.7 |
| 10 | 10thDwellTime | 1.3 | AvDwellTime | 1.7 |
Таблица 4: Топ-10 характеристик согласно их влиянию.
Предполагаемая расшифровка характеристик в таблице 10:
- QueryDomCTR — CTR домена по запросу;
- BM25;
- QueryUrlCTR — CTR документа по запросу;
- QDwellTimeDev — стандартное отклонение от среднего времени пребывания на документе по запросу;
- PageRank;
- AvSatSteps — среднее количество удовлетворенных шагов;
- AvDwellTime — общее среднее время пребывания посетителя на документе по разным поисковым запросам;
- DwellTimeDev — стандартное отклонение от среднего времени пребывания на сайте;
- 90thDwellTime — верхний дециль, он же 90-й персентиль среднего времени пребывания на сайте;
- 10thDwellTime — нижний дециль среднего времени пребывания на сайте;
- TimeOnDomain — время на сайте;
- ComulativeDev — совокупное отклонение.
7. Вывод
Мы провели масштабное исследование посткликовых маршрутов и выяснили, как полученные данные можно использовать для улучшения качества поиска. Был рассмотрен широкий набор характеристик поискового маршрута как потенциального источника информации о предпочтениях пользователя, которые проявляются далеко за пределами страницы результатов выдачи. Подробный анализ показал, что учет особенностей поискового маршрута может существенно улучшить существующий алгоритм поиска. Насколько нам известно, большинство качеств поискового маршрута никогда ранее не оценивались по IR-метрикам. Мы считаем, что исследования новых качеств поисковых маршрутов и различных способов их интерпретации усовершенствует поисковую модель еще больше, чем уже известные поведенческие факторы.
8. Литература
[1] E. Agichtein, E. Brill, and S. Dumais. Improving web search ranking by incorporating user behavior information. In SIGIR, pages 19–26, 2006.
[2] M. Bilenko and R. W. White. Mining the search trails of surfing crowds: identifying relevant websites from user activity. In WWW, pages 51–60, 2008.
[3] Q. Guo and E. Agichtein. Smoothing clickthrough data for web search ranking. In SIGIR, pages 355–362, 2009.
[4] Q. Guo and E. Agichtein. Beyond dwell time: estimating document relevance from cursor movements and other post-click searcher behavior. In WWW, pages 569–578, 2012.
[5] A. Singla, R. White, and J. Huang. Studying trailfinding algorithms for enhanced web search. In SIGIR, pages 443–450, 2010.
[6] K. Wang, T. Walker, and Z. Zheng. Pskip: estimating relevance ranking quality from web search clickthrough data. In KDD, pages 1355–1364, 2009.
[7] R. W. White and S. M. Drucker. Investigating behavioral variability in web search. In WWW, pages 21–30, 2007.
[8] R. W. White and J. Huang. Assessing the scenic route: measuring the value of search trails in web logs. In SIGIR, pages 587–594, 2010.